
This article takes introduces you to the concept of data partitioning in SQL server 2005. It also gives you an example of how to start from the scratch and also how to partition an already existing table.
Data Partitioning:
Partitioning is a very powerful feature in SQL Server 2005. It means that you can horizontally partition the data in your table, thus deciding in which filegroup each row must be placed.
This allows you to operate on a partition even with performance critical operation, such as reindexing, without affecting the others. In addition, during restore, as soon a partition is available; all the data in that partition are available for quering, even if the restore is not yet fully completed.
Illustration of Data Partitioning:
Before proceeding with the steps that are given below, create a database called datapart in your server.
1. Create the file groups in which you are going to place the data
Alter database datapart add filegroup data_part
Alter database datapart add filegroup data_part1
2. Create the files in which you are going to place the data and assign them to the filegroups
Alter database datapart add file (name = 'part1',
filename = 'f:\sugesh\data\part1.ndf') to filegroup data_part
Alter database datapart add file (name = 'part2',
filename = 'f:\sugesh\data\part2.ndf') to filegroup data_part1
3. Create a partition function that partitions the table data in interval of 500 which means that the values below 500 will be placed in partition 1 and others in partition 2.
create partition function part(int) as range right for values (500)
4. Create a partition scheme so that you can associate the partition function to the filegroups
create partition scheme part as partition part to (data_part, data_part1)
5. Create a table to test our data partitioning
create table datapart(name varchar(10), part int) on part(part)
6. Insert values into the tables to the right and left of your partition value.
insert into datapart values('sugesh',0)
insert into datapart values('kumar',499)
insert into datapart values('sugesh',500)
insert into datapart values('sugesh',10000)
7. Select the values from the table along with the partition file id to find where the data has been placed and confirm if the data has been placed as per data partition defined.
select *, $partition.part(part) from datapart
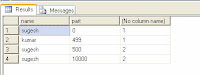
The values 1 and 2 that you see in the last column in the figure given above is the partition id field and as you see all values below 500 are placed in partition 1 and others in partition 2.
Now, what’s up for us next? I have been asked by some of my colleagues, friends and few others that, is it possible to partition a table that already has rows in it. Yes of course, given below are the steps that I have used to partition the data that we have in a table with the data partition feature in SQL Server 2005.
1. Create a table without specifying any data partition in the table.
create table datapart1(name varchar(10), part int) on part(part)
2. Insert values into your table such that the values are split across your partitions.
insert into datapart1 values('sugesh',499)
insert into datapart1 values('sugesh',999)
3. Create a partition function that partitions the table data in interval of 500 which means that the values below 500 will be placed in partition 1 and others in partition 2.
create partition function part(int) as range right for values (500)
4. Create a partition scheme so that you can associate the partition function to the filegroups
Create partition scheme part as partition part to (data_part, data_part1)
5. Insert all the value that you have in the table into a backup table
select * into datapart1_2007jun25 from datapart1
6. Drop and re-create the table specifying the data partitioning that needs to be used.
drop table datapart1
go
create table datapart1(name varchar(10), part int) on part(part)
7. insert the values into the table that you have created with data partitioning from the backup table that has the original values
insert into datapart1
select * from datapart1_2007jun25
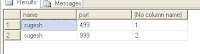
8. Select the values from the table along with the partition file id to find where the data has been placed and confirm if the data has been placed as per data partition defined.
select *, $partition.part(part) from datapart1
Alternate Suggestions:
Though there are other options of using the alter table…. Split partition, alter table…..switch partition they can’t be effectively used for a table that already has large number of rows in it with clustered and non-clustered indexes. This solution of mine worked a way to get them around.
Conclusion:
I hope you have enjoyed learning the way of partitioning the data in SQL Server 2005. The simplest way to partition the data and improve the performance of reads and writes for larges tables. Your opinions, views and suggestions are always welcome.



No comments:
Post a Comment